
如何使用 PyTorch 进行图像分类

如何使用 PyTorch 进行图像分类 #
有小伙伴问了:人工智能和深度学习到底有什么区别?

深度学习一般是用 Python 写的,人工智能一般是用 PPT写的。
小伙伴:那我还是学深度学习好了,但是那些图片文件怎么就可以送到模型里面去呢?我需要打印出来吗?
 你不需要打印出来!
你不需要打印出来!
数字图像由像素组成,像素由一系列代码表示的原色组合而成(例:红绿蓝三通道的彩色图像,单通道的黑白图像),通道是与彩色图像大小相同的灰度图像


黑白图像(单通道)和彩色图像(三通道)
在灰度图像中,0 通常表示黑,而最大值通常表示白色。例如,在一个 8 位影像中,最大的无号整数是 255,所以这是白色的值,下图方便小伙伴理解。

于是这个图片就可以以矩阵的形式进行表现:


{kind=link}
小伙伴:脑袋都会了,就是手有点跟不上。
不要惊慌,接下来就是用 PyTorch 完成的一段简单的代码实现,看看如何实现:
import torch
import random
import numpy as np
import seaborn as sns
import torch.nn.functional as F
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from tqdm import tqdm
from torchvision import datasets, transforms准备数据 #
图像数据在操作系统中普遍是以图像文件形式存在的,例如:jpg、png、jpeg、avi 等等。甚至视频数据也可以简单的理解为一张张图像数据叠加,当然视频数据会用很多视频协议约束,只是暂时可以这样想方便理解。
下面这段代码就是将我们需要的数据转换成 PyTorch 中神经网络模型“认识”的格式 -- Tensor。
transform=transforms.Compose([
transforms.ToTensor(),
])
dataset1 = datasets.MNIST(
'/home/featurize/data',
train=True,
download=True,
transform=transform
)
dataset2 = datasets.MNIST(
'/home/featurize/data',
train=False,
transform=transform
)
train_loader = torch.utils.data.DataLoader(dataset1, batch_size=512)
test_loader = torch.utils.data.DataLoader(dataset2, batch_size=512)class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 32, 3, 1)
self.conv2 = torch.nn.Conv2d(32, 64, 3, 1)
self.dropout1 = torch.nn.Dropout(0.25)
self.dropout2 = torch.nn.Dropout(0.5)
self.fc1 = torch.nn.Linear(9216, 128)
self.fc2 = torch.nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
model = Model().cuda()使用 TensorBoard 可以查看该模型的结构:

criterion = torch.nn.CrossEntropyLoss()优化器 #
优化器,是用于最小化误差函数(损失函数)算法或方法。
这是什么意思呢?比如背化学元素周期表,第一遍:氢氦锂饕旮茕餮旯%#@。。。但是多读几遍就可以背了。
优化器也是这样,在神经网络模型的训练过程中,会逐渐逼近全局最优。
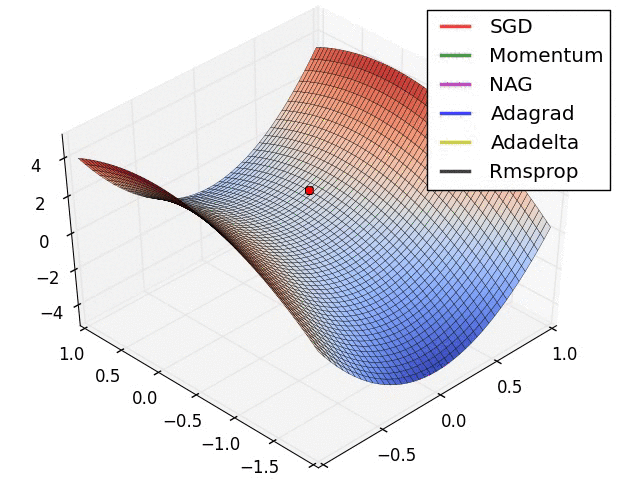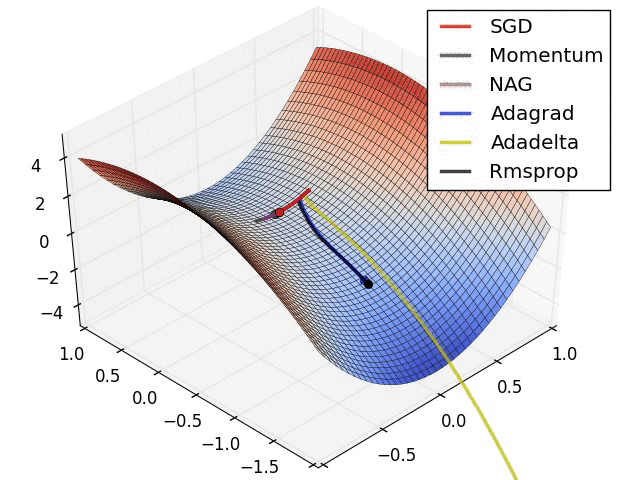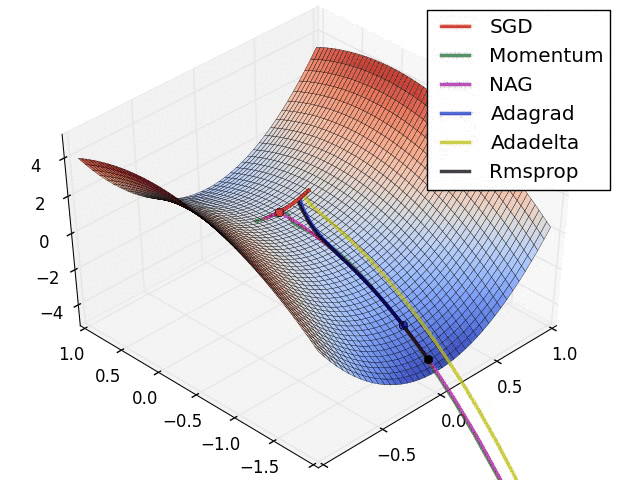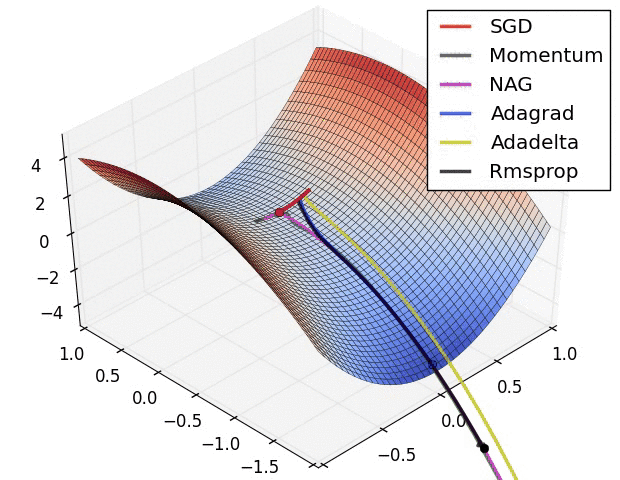
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)amp = True
losses = []
epochs = 10
print('Start training...')
running_loss = 0.0
for epoch in range(epochs):
for i, data in enumerate(train_loader):
inputs, labels = data
inputs, labels = inputs.cuda(), labels.cuda()
optimizer.zero_grad()
if amp == False:
scaler = torch.cuda.amp.GradScaler()
autocast = torch.cuda.amp.autocast
with autocast():
outputs = model(inputs)
loss = criterion(outputs.squeeze(), labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
losses.append(loss.item())
print(f'Epoch: {epoch + 1} Loss: {loss.item()}')
print('Training Finished.')Start training... Epoch: 1 Loss: 2.0722591876983643 Epoch: 2 Loss: 0.7566283345222473 Epoch: 3 Loss: 0.6012440323829651 Epoch: 4 Loss: 0.4330746829509735 Epoch: 5 Loss: 0.5116708874702454 Epoch: 6 Loss: 0.44722819328308105 Epoch: 7 Loss: 0.3877495527267456 Epoch: 8 Loss: 0.40162554383277893 Epoch: 9 Loss: 0.42336317896842957 Epoch: 10 Loss: 0.3293791711330414 Training Finished.
f, ax = plt.subplots()
sns.lineplot(x=np.linspace(0, 0+epochs-1, epochs), y=losses).set_title('Training Loss');
上图只是训练数据集的损失函数,通常我们会用交叉验证集的损失函数来判断模型效果是否良好。
小伙伴问了:为什么要另外一个数据集来验证呢?这多麻烦啊。
模型老做同样的选择题把答案背下来了怎么办,我得确定他是真的会了才行。
下面对测试集进行结果预测:
for img, label in test_loader:
pred = model(img.cuda())
label = torch.argmax(pred, axis=1)
breakf, axs = plt.subplots(2,10, figsize=(16,4))
random_index = [random.randint(0, 128-1) for i in range(20)]
for i in range(2):
for j in range(10):
axs[i][j].set_axis_off()
axs[i][j].set_title(f'Label {label[random_index[i*10+j]]}')
axs[i][j].imshow(img[random_index[i*10+j]].permute(1,2,0), cmap=cm.gray)
结果还是挺不错的,至少随机的这 20 个样本里没有错误。

评论(0条)